Supervised Learning
A Machine Learning approach has an underlying philosophy of taking a labeled data set and extracting information from it and can label new data sets in future. OK! That was quite the textbook type definition, so lets simplify it. Supervised learning is nothing but taking some examples of input and their corresponding output and using the “knowledge” you extract from the data at hand to predict the output values of new inputs in future.
Let try an example - consider the below table, here the value x1 and x2 when fed through a function f produce a value y. The task is to find the function f, which would fit the labeled data. What we mean by fitting the labeled data is that the function f is able to predict the value y with minimal error. Once we find the function f, we can use the same function to predict unknown y for x‘s.
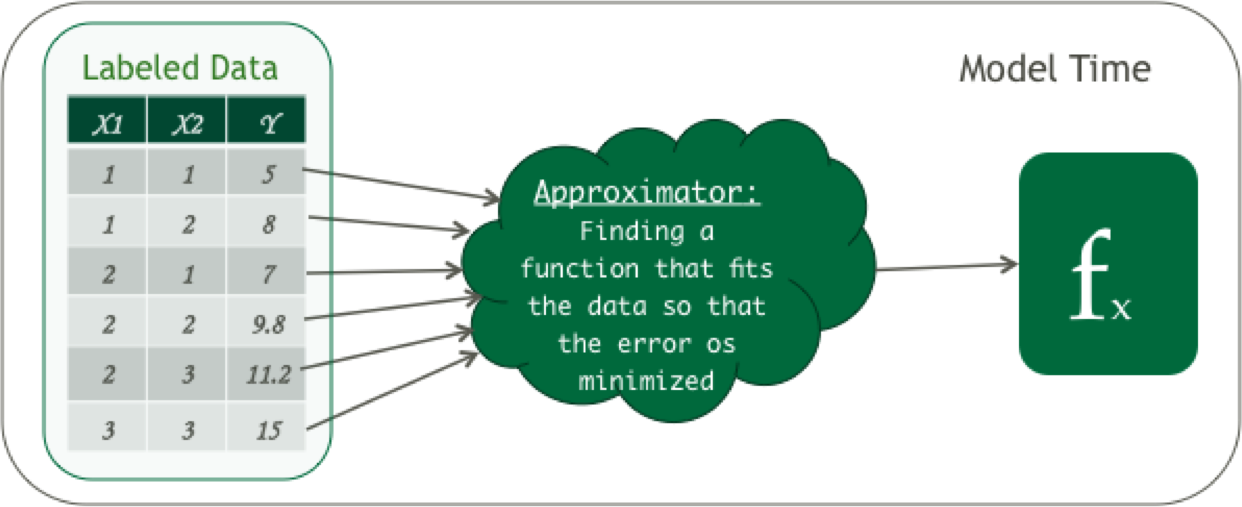
In the above table is your labeled data set where X = {x1 , x2}, X is called a feature vector and y is the target value. A feature vector is an n-dimensional vector of numerical values that represents some object, like representing the length of two sides of a triangle and the output is the length of the hypotenuse.
From the above data and with a little math in your head you know that y = 2(x1) + 3(x2)
So what we have done here is basically estimated an equation(fx) that maps the feature vector also known as input data to an output/target value.
Such type of supervised learning is called Regression.
So that’s one type of supervised learning, let us consider another example. We as human are very good at generalizing things, we do it daily and we start learning that from the day we are born.
Lets take an example of fruits, when we were in kindergarten, the first thing teachers taught us was A for Apple. We look at the image of an apple and based on the shape, size and color we learn what an apple looks like. So now next time someone shows us some fruit, we are able to classify whether its an apple or not.
The question asked here was whether the object under consideration is a Apple ? This could have only finite set of answer - { Yes , No }.
What we have basically done here is predicted an answer from the set of discrete values, in this case the set of discrete value was { yes , no }.
So what we do here is use a classifier(a function or a algorithm) and map the input space to categories(fixed set of values).
Such type of Supervised Learning algorithm comes under a broader label of Classification.
An example of a application that uses classification algorithm in our day to day life is Spam Filtering Classifier which classifies the data into Spam and Not Spam so that your inbox is clean and you don’t get a random Viagra Ad or an ad stating you just won another $1 Billion(as much as I wish it was true).
Summary
The goal of supervised learning is to find a way to generalize data. What we mean by generalizing is to be able to find a way to we can predict the target variable for majority of the input data, even if it is with some error. Generalization could be defined as the ability of the learned algorithm to accurately predict the output for new input data, higher the accuracy better the generalization.
That’s it for this article, I have intentionally kept the math behind this algorithm hidden for now. We shall discuss it when we try to dissect various such algorithms in the near future.
Next article Unsupervised Learning.